먼저 ELB와 Auto-Scailing에 대해 알아보자.
ELB (Elastic Load Balancing)
ELB는 들어오는 애플리케이션 트래픽을 Amazon EC2 인스턴스, 컨테이너, IP 주소 등 여러 대상에 자동으로 분산시킨다.
단일 가용 영역 또는 여러 가용 영역에서 다양한 대상에 걸쳐 애플리케이션 트래픽의 부하를 분산하여 애플리케이션의 결함 허용 능력을 높인다.
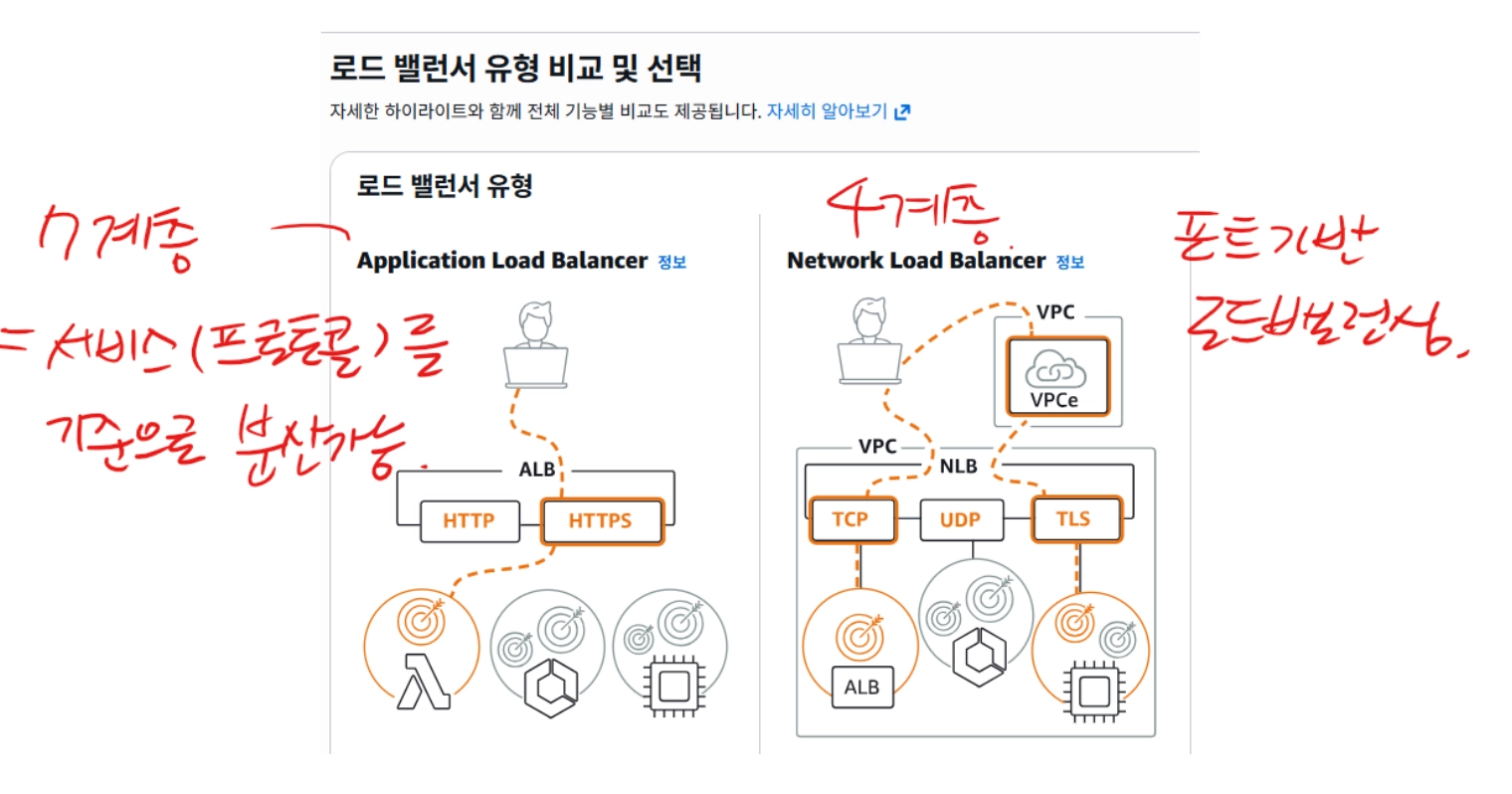
그 중 ALB(Application Load Balancer)의 특징은 OSI 모델의 7계층(애플리케이션 계층)에서 작동하며 HTTP/HTTPS 프로토콜의 헤더 내용을 기반으로 고급 라우팅 결정을 내릴 수 있다.
NLB(Network Load Balancer)는 OSI 모델의 4계층에서 작동하며 초당 수백만 개의 요청을 처리할 수 있는 성능을 제공한다. 또한 가용 여역당 하나의 고정 IP를 가질 수 있다는 큰 특징이 있다.
쉽게 얘기해보면 웹서비스를 운영한다면 ALB를, 게임 서버나 실시간 스트리밍이라면 속도가 생명인 NLB를 사용한다고 볼 수도 있겠다.
Auto-Scailing
Amazon EC2 Auto-Scailing은 애플리케이션의 부하를 처리할 수 있는 정확한 수의 EC2 인스턴스를 유지할 수 있게 도와준다.
지정된 조건에 따라 EC2 인스턴스를 자동으로 시작하거나 종료한다. 이를 통해 수요가 급증할 때는 성능을 유지하고 수요가 적을 때는 비용을 절감한다.
가장 큰 목적은 고가용성(High-Availability)이다.
scale out = 서버의 갯수가 늘어남, scale in = 서버의 갯수가 줄어듬.
scale up = 서버의 리소스가 증가, scale down = 서버의 리소스가 감소.
Auto-Scailing의 구성 순서는 아래와 같다.
- ELB를 생성하면서 빈 타겟그룹을 생성한다.
- 빈 타겟그룹으로 로드밸런서를 생성한다.
- Auto-Scailing 그룹을 만든 후, 위에서 만든 빈 타켓그룹에 넣어준다.
간단한 실습을 통해 개념을 익히고 감각을 익혀보자.
Web 서버를 ubuntu 24.04 기반으로 생성하여 Auto-Scailing을 구성해보자.
- EC2 인스턴스 개수는 최소 1대 ~ 최대 3대
- 가용 영역 최소 2개 이상(a, c)으로 하는 Auto-Scailing 가능한 web 서버들을 프라이빗 서브넷에 위치.
- stress 패키지가 재부팅 시에도 자동으로 부하가 걸리게끔.
- 외부(노트북의 브라우저)에서 웹페이지가 보이도록.
- ALB의 Listen Port : 88
Web 서버(인스턴스)를 생성할 때 퍼블릭으로 둔 후 필요한 패키지를 설치하고 인스턴스를 이미지 화 하여 프라이빗 서브넷에 인스턴스를 생성하는 방향으로 진행하였다.

먼저 퍼블릭 서브넷에 인스턴스를 하나 만들어서 nginx, stress(cpu 부하용) 패키지를 설치한 후 이미지화 하여 시작 템플릿을 만든다.
apt update -y && apt install -y nginx
echo web_tem > /var/www/html/index.html
systemctl enable --now nginx
stress 패키지 설치 후 cpu에 부하 걸어주기.
apt install -y stress
stress -c 2 -t 1200t3.micro의 vcpus 갯수가 2개 이상이므로 -c 2, -t초
20분 동안 2 core cpu에 100% 부하를 준다.

tee /etc/systemd/system/stress.service<<EOF
[Unit]
Description=Run stress test on boot
After=network.target
[Service]
Type=simple
ExecStart=/usr/bin/stress -c 2 -t 1200
Restart=no
[Install]
WantedBy=multi-user.target
EOFstress를 데몬화.
systemctl daemon-reload
systemctl enable stress시스템 반영 후 재부팅 시에도 stress를 주도록 설정한다.
여기까지 했다면 이제 이미지(AMI)를 생성하고 시작 템플릿을 생성해준다.
1. 로드 밸런서 생성

Internet-facing을 선택하고 2개의 가용 영역을 생성해주는데 퍼블릭 서브넷으로 설정을 해준다.
보안 그룹은 22번과 80번 포트가 열린 보안그룹을 선택한다.
여기서 대상 그룹을 생성해줘야 한다.

대상 그룹 생성 탭에 들어가 빈 타겟 그룹을 생성해준 뒤 돌아와서 생성한 대상 그룹을 선택해 준다.
2. Auto-Scailing 그룹 생성
다음으로 Auto-Scailing 그룹을 생성해줘야 한다.
여기서도 2개의 가용 영역을 생성해주는데 서브넷은 프라이빗 서브넷에 위치시킨다. (EC2 인스턴스가 프라이빗 서브넷에 생성되어야 하므로)
기존의 로드 밸런서에 연결하는 설정을 해주고 위에서 만들었던 로드 밸런서 대상 그룹을 선택해준다.
지금부터가 중요하다.

"ELB 상태 확인 켜기"를 체크해주고,

원하는 용량, 최소 용량, 최대 용량을 정의한 뒤 정책 이름을 설정해준다.

목표 CPU 사용률은 70%로 설정한다. 평균 CPU 사용률이 70%를 넘어서면 Auto-Scailing이 인스턴스를 늘려야겠다라고 판단해 새로운 인스턴스를 생성한다. 여기서 새로운 인스턴스는 기존에 생성된 인스턴스 스펙과 동일하게 생성된다. (아까 만든 시작 템플릿을 바탕으로)

이 부분을 체크해주면 CloudWatch에서 지표를 볼 수 있다.

최종적으로 88번 포트로 접속하면 잘 뜨는 것을 확인할 수 있다.
평균 CPU 사용률이 70%가 넘어가면 인스턴스가 최대 3개까지 늘어나도록 설정했다. 필요시 사용률이 줄어들면 인스턴스가 줄어들도록 scale in 정책을 만들 수 있다. 이 부분도 평균 CPU 사용률을 정의해주면 해당 값 이하로 떨어질 경우 Auto-Scailing이 인스턴스 갯수를 줄인다.

CloudWatch 콘솔에 접속해 지표를 보면 CPU 사용률을 확인할 수 있다.
(미처 CloudWatch에서 지표 확인 화면을 캡처하지 못해 비슷한 상황인 다른 사용자의 CloudWatch 이미지를 가져왔다.)
경보 알람이 발생하면 Auto-Scailing이 발생하고 인스턴스가 늘어나고 줄어드는 동작을 진행한다.

Auto-Scailing 흐름을 보면 이런 느낌일 것이다.
지금까지 구성한 실습을 보면 이러하다.
ALB가 퍼블릭 서브넷에 위치하여 외부 손닙을 맞이하는 입구 역할을 하고 EC2는 프라이빗 서브넷에 숨서어 실제 서비스를 제공한다.
외부 사용자는 ALB(88포트)로 들어오고, ALB는 내부망을 통해 EC2(80포트)로 연결을 토스한다. 인스턴스는 공인 IP가 없어도 ALB 덕분에 안전하게 서비스할 수 있다.
시작 템플릿은 서버를 만들 때 필요한 붕어빵 틀이라고 생각하면 편하다
Auto-Scailing 그룹을 생성하고 scale out(확장), scale in(축소) 정책을 생성해 CPU 부하에 따라서 시작 템플릿을 활용해 서버를 자동으로 생성하고 삭제한다.
이 과정에서 궁금증이 생겼다.
"그럼 CPU 사용률이 떨어져 인스턴스가 삭제될 때 해당 인스턴스에 남아있는 사용자는 안 튕기나?"
삭제 결정이 내려진 서버에는 더 이상 새로운 사용자를 보내지 않는다.(배수 상태, Draining) 이미 접속 중인 손님이 볼일을 마칠 때까지 설정된 시간(기본 300초)동안 기다려 준다. 시간이 다 되면 사용자가 남아있더라도 연결을 끊고 서버를 종료한다. (이때 브라우저는 자동으로 다른 살아있는 서버에 재접속을 시도한다.) 그래서 사용자 입장에서는 잠깐의 딜레이가 발생하고 다른 큰 이슈 없이 사용할 수 있게된다.
좋은 인프라륵 구축하는 것도 중요하지만 이 속에서 "사용자가 장애를 느끼지 않게 하는 것"이 가장 큰 핵심인 것 같다. ALB와 Auto-Scailing의 조합은 단순한 자동화를 넘어 서비스의 연속성을 보장하는 강력한 도구인 것 같다.
'Infra > AWS' 카테고리의 다른 글
| AWS Summit SEOUL 2026 후기 (0) | 2026.05.21 |
|---|---|
| 클라우드 환경에서 DB를 어떻게 안전하고 효율적으로 관리할까? (feat. AWS RDS) (0) | 2026.03.24 |
| 가상 네트워크 만들기 - AWS VPC 설계 및 프라이빗 서브넷 통신 (0) | 2026.03.22 |
| 인프라와 데이터 보호 (feat. AWS Technical Essentials) (0) | 2026.01.27 |